Así es, tal y como sus ojos lo leen, esta vez les traigo una entrada referente a la librería node.js.
Para comenzar instalaremos el paquete, para ello es lo siguiente.
https://nodejs.org/es/download/
Dependiendo del caso que lo requiera Windows, Linux o Mac.
Una vez instalado, comprobamos la librería abriendo la terminal o linea de comando, con la orden.
C:\>_ node --version
Para continuar es necesario seguir estos pasos.
1.- Crear un directorio
2.- En el directorio nuevo, crear el init con node.
3.- Descargar los módulos necesarios para la aplicación requerida.
Con todo esto aclarado aremos nuestro primer "Hola mundo" desde node.js, Manos a la obra.
En xampp/htdocs: creamos la carpeta holamundo, desde cmd nos posicionamos en la carpeta holamundo e indicamos.
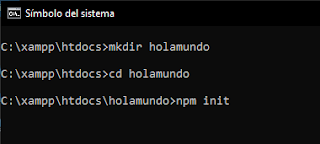
El resultado debería ser el siguiente.

Esto nos deja un archivo package.json el cual ira cargando los módulos que se instalen.
Dentro de hola mundo, creamos un archivo js llamado index.js, el cual contendrá el siguiente código...
Para comenzar instalaremos el paquete, para ello es lo siguiente.
https://nodejs.org/es/download/
Dependiendo del caso que lo requiera Windows, Linux o Mac.
Una vez instalado, comprobamos la librería abriendo la terminal o linea de comando, con la orden.
C:\>_ node --version
Para continuar es necesario seguir estos pasos.
1.- Crear un directorio
2.- En el directorio nuevo, crear el init con node.
3.- Descargar los módulos necesarios para la aplicación requerida.
Con todo esto aclarado aremos nuestro primer "Hola mundo" desde node.js, Manos a la obra.
En xampp/htdocs: creamos la carpeta holamundo, desde cmd nos posicionamos en la carpeta holamundo e indicamos.

El resultado debería ser el siguiente.

Dentro de hola mundo, creamos un archivo js llamado index.js, el cual contendrá el siguiente código...
var http = require( "http" );
http.createServer( function( req, res ){
res.writeHead( 200, {
'Content-Type':'text/plain'
});
res.end( 'hola Mundo\n' );
}).listen( 8420 );
console.log( 'servidor en url http://localhost:8420' );
Al final, damos el comando.
 nos colocamos en nuestro navegador en el puerto indicado y listo, tenemos nuestro hola mundo echo en node js
nos colocamos en nuestro navegador en el puerto indicado y listo, tenemos nuestro hola mundo echo en node js
No olvides dejarme tu comentario.
Si puedo ayudarte en algo escribeme.
Asta la próxima.
http.createServer( function( req, res ){
res.writeHead( 200, {
'Content-Type':'text/plain'
});
res.end( 'hola Mundo\n' );
}).listen( 8420 );
console.log( 'servidor en url http://localhost:8420' );
Al final, damos el comando.

No olvides dejarme tu comentario.
Si puedo ayudarte en algo escribeme.
Asta la próxima.




